Architecture of Conveyor
Conveyor consists of two components:
- The control plane, which implements the Conveyor REST API as well as the Conveyor UI and is operated by Conveyor team.
- The data plane, which consists of many resources, most notably a Kubernetes cluster and the Conveyor components running on top of it. All of them are installed in the client's cloud environment (AWS or Azure).
Both the data plane and control plane are supplied to clients as a service. They are monitored, updated and maintained by the Conveyor team for you, allowing you to focus on implementing business logic without having to deal with the complexity of keeping your infrastructure secure and up-to-date.
Conveyor engineers only need access to the client's cloud account during installation and (currently) for maintenance and updates. All client data and client code is pushed and stored directly to the data plane which runs in your own account.
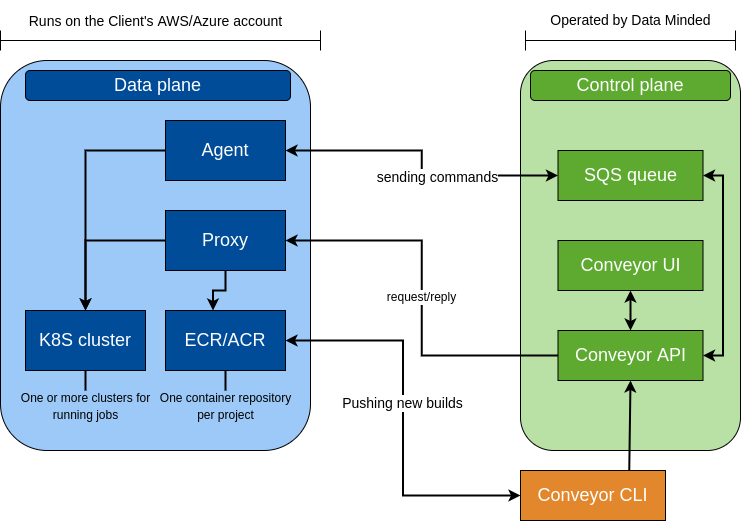
Control plane
The control plane is operated and maintained by the Conveyor team. The control plane API as well as the UI are exposed to the Internet and handles client requests allowing them to trigger builds, create environments and create projects. The control plane has permission to post messages to an SQS queue within the data plane. If authentication is successful and clients are authorised to perform the requested action, the control plane will post messages to this queue, instructing the data plane to perform the requested action.
You can interact with the control plane API using the Conveyor CLI or use the terraform provider, which implements a subset of the functionality mainly concerned to managing projects/users.
Data plane
The Conveyor data plane is the collection of Conveyor components installed in the client's cloud environment. At the moment we support both AWS and Azure clouds. Components of the data plane include:
- The Conveyor agent (which runs on AWS Fargate or AKS). It listens to events that are sent to a queue (AWS SQS) by the control plane, and that tells it to perform actions such as "create a container repository", "create an environment" or "deploy a new build to an environment".
- The Conveyor container registry (which can be ECR or ACR). The Conveyor container registry is where builds of projects are stored in the form of OCI images.
- The Conveyor Kubernetes cluster (EKS, AKS). The Conveyor Kubernetes cluster is where jobs run, but also where e.g. the Airflow servers live. All Conveyor environments run on the same Kubernetes cluster, but within a different namespace.
- An extensive collection of IAM roles or User managed identities.
- The Conveyor proxy. It is a GRPC API which is used for request/reply communication between the control- and data plane.
The data plane AWS/Azure infrastructure is described in Terraform, and is currently installed and initialised in the client environment by the Conveyor team. Initialisation of the data plane requires creating all the resources described above and more, and therefore requires comprehensive, administrator-like permissions. After the data plane is created, these privileges are no longer needed and can be revoked.
To do its job, the Conveyor agent itself is assigned a fairly extensive set of permissions, since it needs to be able to initialise jobs that can perform useful tasks. Note that it is not possible for the Conveyor team to assume the role of the Conveyor agent.
Currently, updating the data plane is automated by the Conveyor team. When a new release is available, your installation will be automatically updated. Updating requires the same set of permissions as the initial deployment.