Airflow
A Conveyor environment comes with a managed Airflow installation. If you are new to Airflow, please have a look at the architecture overview. The high-level architecture is as follows:
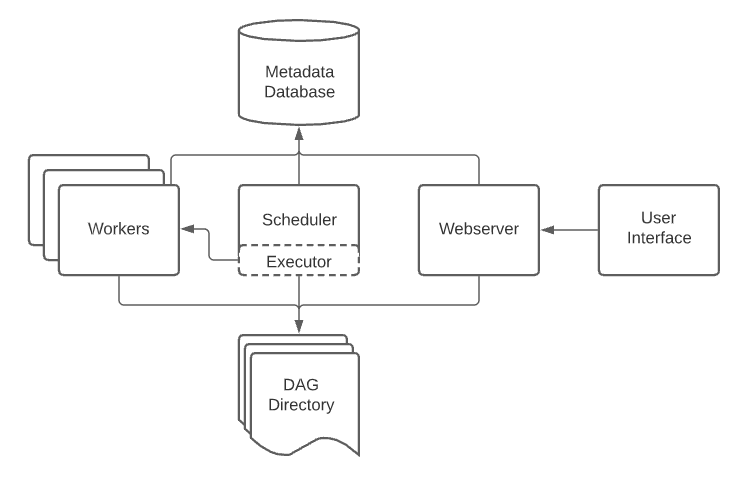
Based on the general architecture, let's go over how Conveyor configures Airflow:
- Scheduler: The Airflow scheduler is responsible for triggering tasks based on the schedule information provided in the dags folder of your project. Conveyor ensures that all dags of the different projects deployed in the same environment are mounted such that the scheduler can manage them.
- Executor: We configure Airflow to use the
Kubernetes executor, meaning that every task that needs to run is scheduled as a Kubernetes pod in your Kubernetes cluster. More details can be found in the Airflow Kubernetes documentation - Webserver: Web interface of Airflow that we also deploy in every Conveyor environment such that users can easily monitor/interact with their DAGS. We use a couple of hooks to be able to navigate from Airflow to the Conveyor UI, most importantly to go from the Airflow task details to the Conveyor application runs for inspecting the logs of Conveyor pods.
- Airflow Database: We create one database server for every Kubernetes cluster and every Conveyor environment uses a separate database within that server.
- Workers: Every task in Airflow gets a dedicated Airflow worker pod that is responsible for executing the task
and updating the result of the task_id in the Airflow database.
Most tasks in Conveyor use a predefined template, called an operator (e.g.
ConveyorContainerOperatorV2,ConveyorSparkSubmitOperatorV2). The goal of these operators is to make it easy to run a container/Spark job through Airflow.
Airflow task execution
Scheduling a task involves many components, and it is important to understand how they interact in order to work well with Conveyor. The following sequence diagram describes the full flow for a Container job. A Spark job follows the same sequence from Airflow's perspective, only internally in Conveyor there are more moving parts.
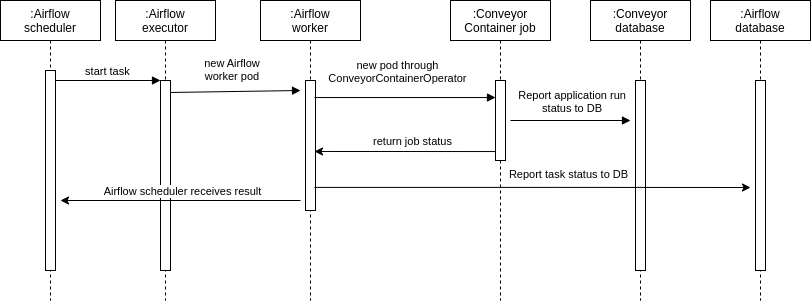
This also shows why there are two different places to look for logs for your task.
- On one side we have the Airflow worker logs, which are managed by Airflow and accessible through the Airflow web UI.
- On the other side we have the Conveyor logs, which are stored in cloudwatch and made available in the Conveyor UI.
Since Conveyor has no control over the Airflow worker and its logs, we cannot show them in the Conveyor UI.
How are spot interruptions handled?
When a Container/Spark job is running on a spot node, it can be interrupted by your cloud provider when the spot price exceeds the bid price. In Conveyor the same lifecycle is used for both the Airflow workers and the executed task, as shown on the sequence diagram above. A spot interrupt can thus originate from either the node on which the Airflow worker ran or the node where the Conveyor task was running. Both cases are handled in Conveyor:
- When the Airflow worker is interrupted, Conveyor adds a log entry to the Airflow logs indicating that the worker was killed due to a spot interrupt and terminates the Conveyor task. On the Conveyor task, you will see a log entry indicating that the task was terminated externally.
- When the Conveyor task gets spot interrupted, the logs will show that the task failed due to a spot interrupt.
Airflow DAG validation
Writing Airflow DAGS is error-prone as it is easy to make a small mistake (e.g. forgetting an import statement or specifying the wrong method argument).
In order to capture these issues as quickly as possible, we validate your DAG code before building your Docker image.
Alternatively, you can also run the validation explicitly by using the conveyor project validate-dags command.
DAG validation works by running our Airflow docker image, which contains the Conveyor plugin, and mounting all relevant
DAG files in the container, namely: the DAGS of the current project as well as the DAGS for every dependent project.
Packages that are used in your dags will have their versions automatically resolved and the code will be downloaded.
These files are stored under /opt/airflow/dags, which is the default location for DAGS in Airflow.
Next, we create a dagbag based on all the DAG files.
Finally, using the dagbag we can show all the Airflow warnings as well as the import errors for every DAG file.
The validation command fails when there are any errors.
Running DAG validation with a proxy configuration
In certain networking setups, you might want to provide proxy configuration
(i.e. the HTTP_PROXY, HTTPS_PROXY, NO_PROXY environment variables) for containers running on your machine.
The Conveyor CLI will pick up on these environment variables and propagate them to the Airflow container that is run for the DAG validation.
When using the Docker engine,
you can also use the default proxy settings recorded in ~/.docker/config.json in order to provide these environment variables.
Airflow updates
There are 2 ways in which an Airflow environment gets updated:
- When a user deploys a project to the environment by issuing
conveyor deploy --env <env_name>. This will cause the Airflow web and scheduler to be refreshed and restarted. We restart them to ensure that the new dag information is loaded into both the Airflow scheduler and web component. - When the Conveyor team releases a new version of Conveyor. This will change the Airflow image tag and thus cause a rollout of both the scheduler and the web component.
What happens to running jobs when the Airflow instance that started them is itself restarted?
Conveyor runs its containerized jobs as independent pods in Kubernetes.
As these pods run independently of the Airflow instance that started them,
they are unaffected by an Airflow restart and continue running as if nothing happened.
Upon completion, they will update their status based on the task_id in the Airflow database.
The new Airflow scheduler will attempt to restart watching the existing Airflow workers, in order to know when they finished.
In summary, your running jobs are unaffected by updates to the Conveyor environment and will complete normally.
Airflow upgrades
In order to benefit from fixes/improvements in newer versions, the Conveyor team attempts to upgrade the Airflow versions regularly. We do not aim to be on the latest version since we noticed that it can contain a lot of unexpected issues. Therefore, we wait for 1 or 2 bugfix releases to be out before upgrading.
We deliberately choose to limit the number of Airflow providers supported in Conveyor to enable updating the Airflow images in a Conveyor release without impacting our users. This way we can ensure that all environments are on the latest version, and we do not have to support multiple versions at the same time.